时隔五年之后,OpenAI 刚刚正式发布两款开源权重语言模型——gpt-oss-120b和 gpt-oss-20b,而上一次他们开源语言模型,还要追溯到 2019 年的 GPT-2。
🔗 相关阅读:刚刚,OpenAI发布2款开源模型!手机笔记本也能跑,北大校友扛大旗
亮点方面:
- gpt-oss-120b:大型开放模型,适用于生产、通用、高推理需求的用例,可运行于单个 H100 GPU(1170 亿参数,激活参数为 51 亿),设计用于数据中心以及高端台式机和笔记本电脑上运行
- gpt-oss-20b:中型开放模型,用于更低延迟、本地或专业化使用场景(21B 参数,3.6B 激活参数),可以在大多数台式机和笔记本电脑上运行。
- Apache 2.0 许可证: 可自由构建,无需遵守 copyleft 限制或担心专利风险——非常适合实验、定制和商业部署。
- 可配置的推理强度: 根据具体使用场景和延迟需求,轻松调整推理强度(低、中、高)。完整的思维链: 全面访问模型的推理过程,便于调试并增强对输出结果的信任。此功能不适合展示给最终用户。
- 可微调: 通过参数微调,完全定制模型以满足用户的具体使用需求。
- 智能 Agent 能力: 利用模型的原生功能进行函数调用、 网页浏览 、Python 代码执行和结构化输出。
- 原生 MXFP4 量化: 模型使用 MoE 层的原生 MXFP4 精度进行训练,使得 gpt-oss-120b 能够在单个 H100 GPU 上运行,gpt-oss-20b 模型则能在 16GB 内存内运行。
值得一提的是,据 OpenAI 官方介绍,gpt-oss-120b 仅需 80 GB 内存,而 gpt-oss-20b 更是仅需 16GB 内存就能运行。
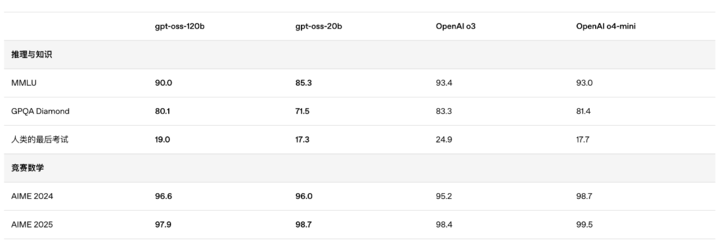
根据 OpenAI 公布的基准测试结果,gpt-oss-120b 在竞赛编程的 Codeforces 测试中表现优于 o3-mini,与o4-mini持平;在通用问题解决能力的 MMLU 和 HLE 测试中同样超越 o3-mini,接近 o4-mini 水平;而参数规模较小的 gpt-oss-20b 在这些相同的评测中仍然表现出与 OpenAI o3-mini 持平或更优的水平。
|
