8 月 11 日,昆仑万维正式发布 SkyReels-A3 模型。
官方表示,SkyReels-A3 模型基于「DiT(Diffusion Transformer)视频扩散模型+插帧模型进行视频延展+基于强化学习的动作优化+运镜可控」,其能实现任意时长的全模态音频驱动数字人创作。
据悉,SkyReels-A3 模型在以下四个方向上为用户带来新体验:
- Text Prompt(文本提示词输入)支持画面变化;
- 更自然的动作交互,包括和商品的交互、说话时的手部动作等;
- 运镜的运用和控制更高级,让艺术场景如音乐/MV 等拥有更高的艺术美感;
- 可以生成单分镜分钟级别视频,支持长达 60 秒的输出;多分镜可以支持无限时长。
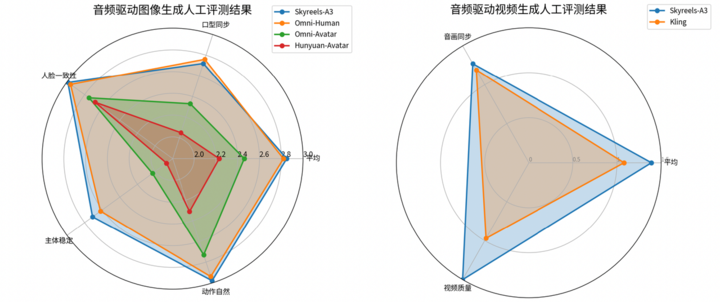
在定量评估中,SkyReels-A3 在不同的音频驱动场景,与先进的开源模型 OmniAvatar 和闭源模型 OmniHuman 等方法进行了对比。结果显示,SkyReels-A3 在大多数指标上超越了这些方法,尤其是在唇形同步(sync-c 和 sync-d)方面表现出卓越的性能。
此外,昆仑万维还采取了人工评测来更充分的反应模型生成的效果。结果显示,SkyReels-A3 对于面部和主体的稳定性,动作自然性都取得了最好的效果,同时在口型同步和人脸取得最好比较接近的结果,并且还在音画同步和视频质量上都有明显的优势。
|
